We’ve just released a paper that shows it was possible to steal part of OpenAI’s ChatGPT or Google’s PaLM-2 (up to an affine transformation) by making queries to their public APIs. Our attack recovers one layer of the model (the final layer) for a few hundred or a few thousand US dollars (depending on the layer’s size, which impacts the number of API queries needed). Our attack also allows us to reverse-engineer the hidden dimension of these models, e.g., we learn the size of ChatGPT.
In this post, we describe the basic idea behind the attack, discuss some of the results, and then talk about the broader implications of attacks like this.
Timeline
We first discovered this attack method back in 2020, but didn’t see any way to actually use it to do anything interesting until October of last year (2023) when we realized that it would actually be effective on the APIs used to serve production language models like ChatGPT.
We implemented a proof of concept attack in November 2023, and sent our responsible disclosure notifications in December. (We notified all services we are aware of that are vulnerable to this attack. We also shared our attack with several other popular services, even if they were not vulnerable to our specific attack, because variants of our attack may be possible in other settings.) After a standard 90-day disclosure period, Google introduced changes to mitigate this vulnerability, with OpenAI following shortly after on March 3rd. Today, we’re releasing our paper.
Attack Method
Our attack is exceptionally simple. For this section, we’re going to assume you have a passing familiarity with linear algebra and knowledge of the transformer architecture (e.g., maybe you took a linear algebra class back in college). If you don’t have linear algebra experience, then feel free to skip to the next section; it suffices to know that the attack is fairly elementary and efficient.
Warm-Up: Stealing the model’s hidden dimension
A transformer is a mathematical function f(x) that takes a sequence of tokens x as input, and returns a “logit vector,” which is just a t-dimensional vector of real numbers where t is the number of unique tokens in the overall vocabulary. (That these real numbers correspond to the probability of the model emitting each token 1 \ldots t is not important for our attack.)
Internally, a transformer is a function f(p) = W \cdot g_\theta(p), where g_\theta is some ugly function that ends with a nonlinearity and W is a single projection matrix. We like to think of g_\theta as layers of transformer blocks, and W as the projection layer that maps hidden state to tokens. But, ultimately, f(x) is just a product between some matrix and some other function.
Now here’s the core insight of our paper. The matrix W is a t \times h-dimensional matrix going from the vector space of hidden values \mathbb{R}^h to the vector space of output logits, one for each \mathbb{R}^t. But the hidden dimension is smaller than the number of tokens, often by quite a bit (i.e., h << t). This means that, while token logits technically live in a t-dimensional vector space, they actually live in a h-dimensional subspace.
So “just” compute the full logit vectors y_i for a bunch of random inputs p_i, then form a matrix Y = [y_0, y_1, ... , y_n], with n > h (in practice, for some large n, e.g., for Llama 65B, n \approx 8192), and then compute the singular value decomposition (SVD) of Y. Because the embeddings live in a h-dimensional subspace we should expect exactly h non-zero singular values of Y.
In practice, of course, we get some noise. So we can’t just count the number of nonzero singular values, but rather the number of “big enough” ones (i.e., ones that aren’t close to 0).
Actually attacking a production API
In practice, no one actually lets you query a language model and view a logit vector of outputs. But they often do let you learn these values, by querying other things and computing them.
Results
We received advance permission from OpenAI to test our model stealing attack on their API. 😈
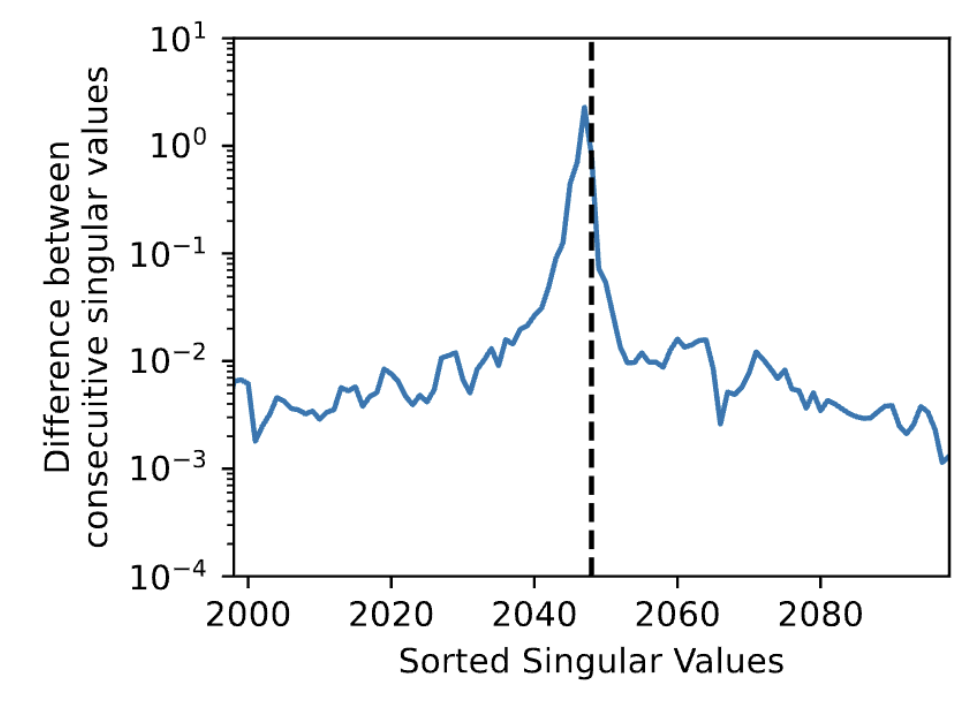
Open Source Model Validation
To validate that our attack works, we implement it on several white-box models. For example, here we show a plot of the difference between consecutive singular values on a Pythia model with hidden dimension 2048. We see that this difference spikes at the 2047th singular value. (Note, we can account for this off-by-one “error” as a loss of dimensionality due to the type of normalization used in the model.) This means that we’ve captured the vast majority of the “variance” in the matrix with 2047 singular vectors, and after the 2047th singular vector, the amount of “variance” left in the matrix dramatically drops off. 😈
Stealing GPT-3 Ada & Babbage
Now that we know it works, we then used our attack to steal the entire final layer of the GPT-3 Ada and Babbage size models. We, also, received approval from OpenAI to run this attack before implementing it. 😈
Stealing GPT-3.5-turbo-chat’s size
Finally, we confirmed that our attack is effective on GPT-3.5-turbo-instruct and GPT-3.5-turbo-chat. We decided against publishing the actual sizes of these models as part of our responsible disclosure argeement, but confirmed with OpenAI that our stolen hidden dimension size was correct (and then destroyed all data associated with this attack). 😈
Consequences
Precise model stealing attacks are practical
Up until now, most people (including us) had written off model extraction attacks as not practical. Yes, you can do some functionality-stealing attack that approximately performs a similar behavior, or you could try to distill a model. But by and large, stealing or distilling a model wouldn’t be more cost effective than just training your own. Further, we didn’t think that a model extraction attack that recovered a model nearly bit-for-bit would be possible.
As we discuss in the paper, prior attacks (including those that some of us have worked on!) required extremely strong assumptions. This includes the ability to query on arbitrary (continuous value) inputs, very high precision inference, and they are still limited to rather small models.
API design matters
Our attack worked because (and only because!) a few model providers made the logit bias parameter available. Model providers (like Anthropic) who did not provide such an API were not vulnerable to this attack. The fact that such a small API design decision can either make an attack possible or completely prevent it is important and implies that APIs should be designed with security in mind.
More practical attacks are (probably) coming
Adversarial ML had somewhat of a bad reputation for a few years. It seemed like none of the attacks we were working on actually worked in practice. Sure you could fool an ImageNet model to classify a panda as a gibbon, but who cares?
This paper shows—again—that all the work the adversarial ML community has been doing over the past few years can directly transfer over to this new age of language models we’re living in.
Also as models are used to create more valuable outputs (outputs that may be otherwise hard or expensive to create), adversarial ML can be used to create outputs that model creators might sorely object to. For example, creating a violent painting is much harder than writing violent text—it’s also much harder than searching Google for potentially harmful information.
FAQ
Can this attack be extended to steal the entire model?
Probably not. Or at least, not a direct extension of this attack.
This attack relies on a fairly specific observation about the way linear transformations work, and so even a single non-linearity would break the attack, and prevents us from learning a second layer of the model.
But we are excited by the possibility of new attacks that might be able to do even better.
How do you prevent this?
Our paper proposes a bunch of ways to prevent the attack. Fundamentally the simplest strategy—the one adopted by OpenAI and Google—was to limit the limit the users’ ability to send queries that supply both logprobs and logit bias. This doesn’t make our attack outright impossible, but it does (fairly significantly) increase the cost of the attack. As mentioned above, other model providers prevented this attack from the beginning by never allowing logit-bias queries.